DeepSeek-V4 深度研究剖析
日期:2026-05-01
视角:大模型研究者 / 架构与工程化联合视角
论文:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
0. 资料来源与定位
Section titled “0. 资料来源与定位”DeepSeek-V4 论文目前的官方主入口是 Hugging Face,而不是 arXiv 页面。
- DeepSeek-V4-Pro:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- DeepSeek-V4-Flash:https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- DeepSeek-V4 collection:https://huggingface.co/collections/deepseek-ai/deepseek-v4
- 本地 PDF:DeepSeek_V4.pdf
- 本地正文抽取:deepseek_v4.txt
一句话定位:DeepSeek-V4 是一篇以“百万 token 上下文效率”为主轴的下一代 LLM 架构与工程系统论文;它不是单纯堆参数,而是试图把 long context、test-time scaling、agent、多专家后训练和低成本服务放进同一个技术栈。
1. 两张核心讲解图
Section titled “1. 两张核心讲解图”图 1:百万上下文注意力压缩机制
Section titled “图 1:百万上下文注意力压缩机制”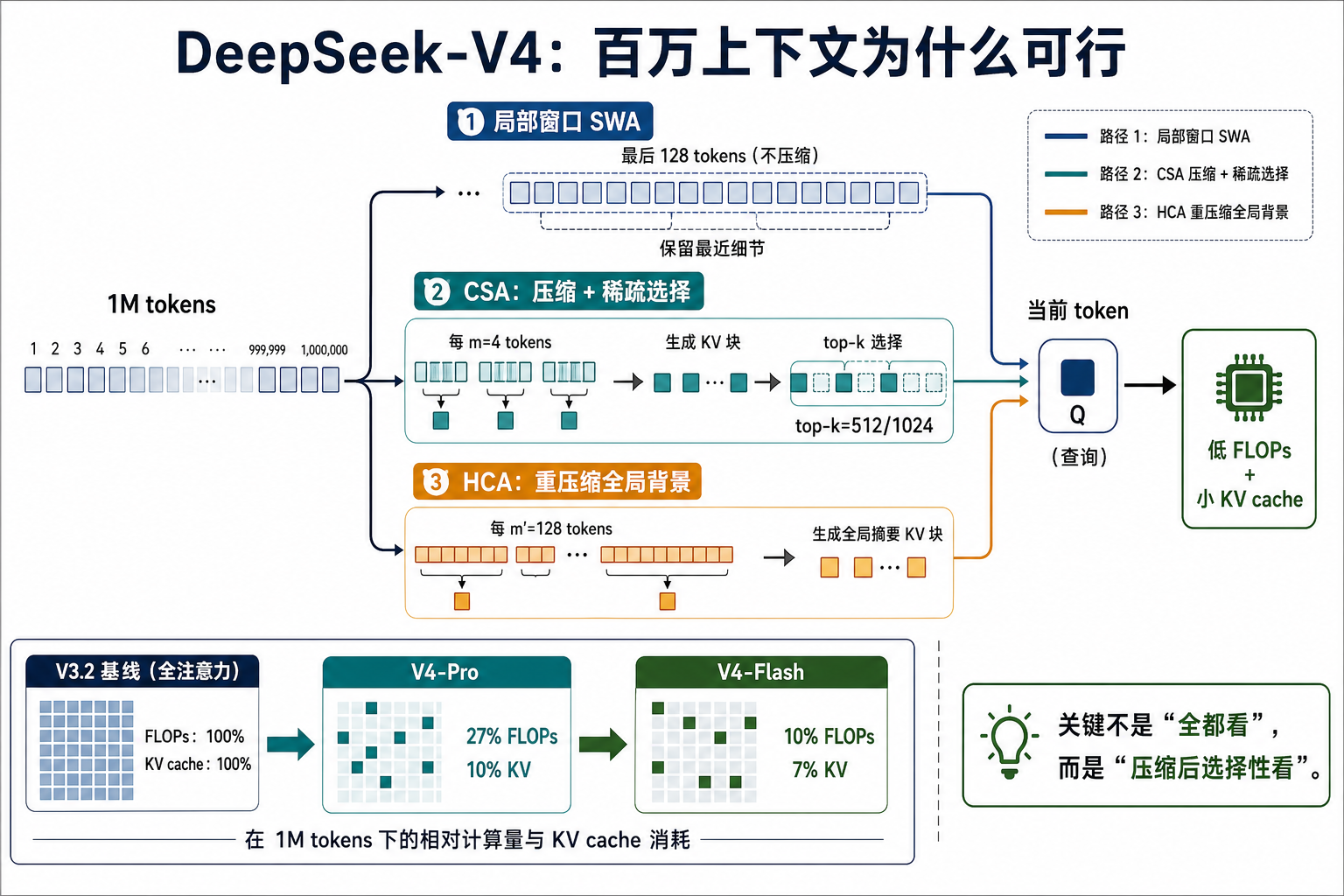
这张图解释 V4 最核心的架构问题:如果上下文到 1M tokens,普通全注意力不可承受。V4 不是“每个 token 都全量看所有历史”,而是组合三条信息路径:
- SWA 保留最近局部细节。
- CSA 把历史 token 先压缩,再用 indexer 选择相关 compressed KV。
- HCA 用更激进压缩保留远程全局背景。
图 2:从预训练到统一专家能力
Section titled “图 2:从预训练到统一专家能力”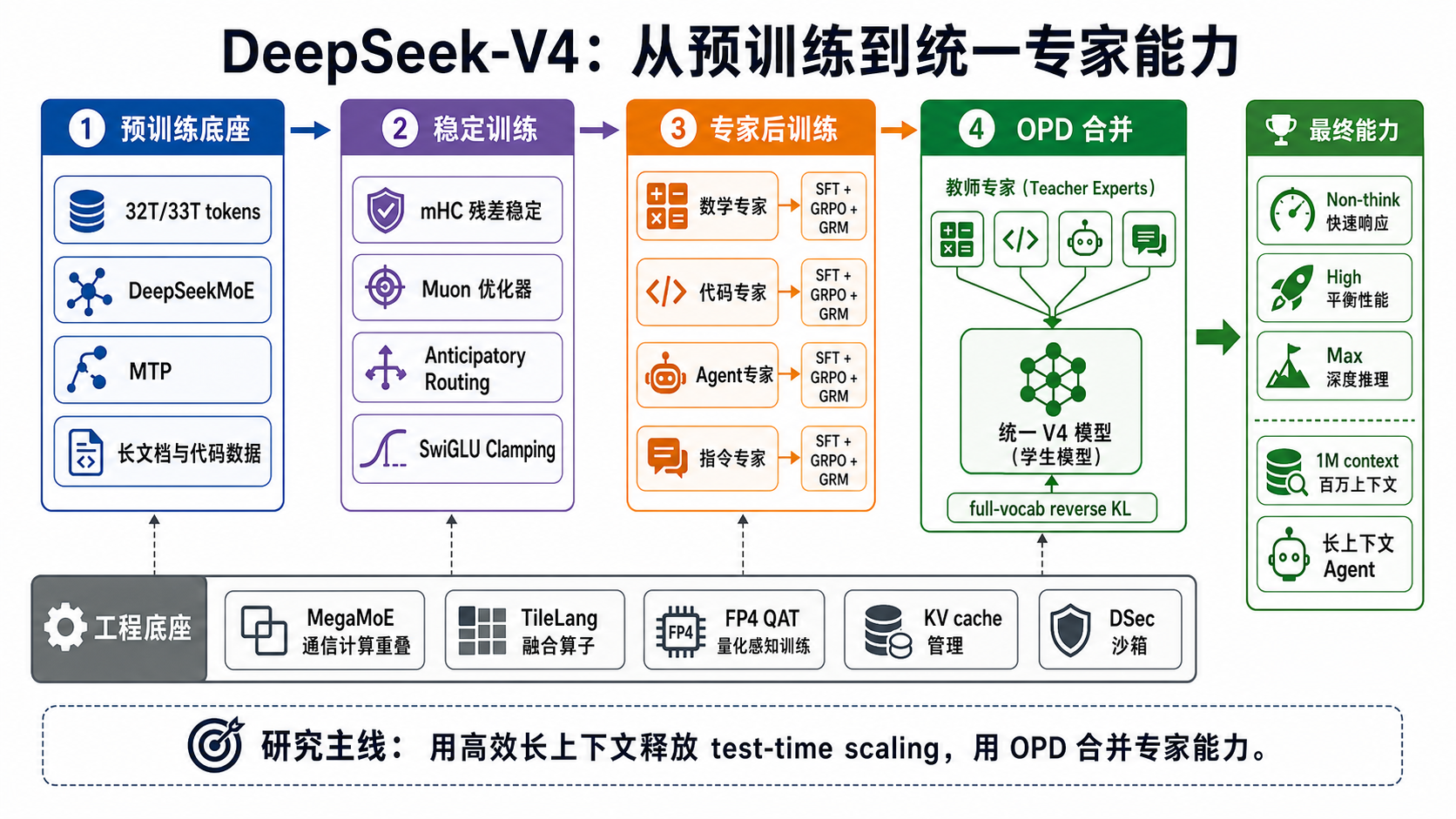
这张图解释 V4 的能力生成路径:先通过 32T/33T tokens 和新架构训练底座,再用 mHC、Muon、Anticipatory Routing 等解决稳定性,随后训练领域专家,最终通过 OPD 合并专家能力,输出 Non-think / High / Max 三种推理模式。
2. 论文主线:为什么 V4 要围绕 1M context 做?
Section titled “2. 论文主线:为什么 V4 要围绕 1M context 做?”V4 论文开篇的核心判断是:推理模型的能力提升越来越依赖 test-time scaling,也就是推理时花更多 token、更多步骤、更多工具调用来求解问题。但传统 Transformer attention 的成本随上下文长度急剧上升,导致长上下文和长推理链成为瓶颈。
从研究角度,V4 试图解决的是三件事的交集:
- 长上下文:1M tokens 级别的输入、检索、代码仓库、论文集合、长文档、长对话。
- 长推理:High / Max reasoning effort 下更长的思维 token 与工具轨迹。
- 长任务:Agent 在数百步工具调用中保持状态、缓存、证据和中间结果。
所以 V4 的核心不是“上下文窗口数字更大”,而是:让百万上下文成为可训练、可推理、可服务的常规能力。
3. 模型家族:Pro 与 Flash
Section titled “3. 模型家族:Pro 与 Flash”V4 系列有两个主要预览模型:
| 模型 | 总参数 | 激活参数 | 定位 |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 更强知识、推理、Agent、复杂任务 |
| DeepSeek-V4-Flash | 284B | 13B | 更高成本效率,推理任务可通过更多 thinking budget 追近 |
论文中有一个很值得注意的结论:Flash 的激活参数只有 13B,但在不少 base benchmark 上已经超过 DeepSeek-V3.2-Base;这说明 V4 的提升不只是参数规模,而是架构、数据质量、训练稳定性和后训练范式共同作用。
4. 总体架构:保留 V3 成熟件,替换长上下文瓶颈
Section titled “4. 总体架构:保留 V3 成熟件,替换长上下文瓶颈”DeepSeek-V4 仍然是 Transformer + MoE 路线,继承了 DeepSeek-V3 的一些成熟设计:
- DeepSeekMoE:细粒度 routed experts + shared experts。
- MTP, Multi-Token Prediction:继续使用多 token 预测目标。
- Auxiliary-loss-free load balancing:保留无辅助损失的负载均衡策略,并加轻量 sequence-wise balance loss。
V4 的新增关键件:
- mHC:增强 residual connection 的表达与稳定性。
- CSA + HCA hybrid attention:解决百万上下文 attention 成本。
- Muon optimizer:提升收敛速度与训练稳定性。
- FP4 QAT / FP8 path / KV cache 工程:把架构优势落到实际训练和推理成本上。
- OPD:用 on-policy distillation 合并多个领域专家。
我的判断:V4 是典型的“架构、训练、系统、后训练”共同设计论文。单独看任何一个模块都未必足以解释结果,真正的贡献在于把这些模块组合到可生产的规模。
5. CSA + HCA:V4 论文最重要的架构创新
Section titled “5. CSA + HCA:V4 论文最重要的架构创新”5.1 为什么普通 attention 不行?
Section titled “5.1 为什么普通 attention 不行?”普通全注意力下,每个 query token 都要和所有历史 KV 交互。上下文从 128K 增到 1M 后:
- prefilling 成本巨大。
- decoding 时 KV cache 内存巨大。
- attention FLOPs 巨大。
- 多轮 Agent 任务中的 shared-prefix 复用也会变复杂。
V4 的设计目标是降低两个量:
- 每个 token 需要读取的 KV 数量。
- 每个请求需要存储的 KV cache 大小。
5.2 SWA:局部窗口保真
Section titled “5.2 SWA:局部窗口保真”SWA, Sliding Window Attention,保留最近 nwin=128 个未压缩 KV。
它解决的是局部语言建模里的近邻依赖。例如当前 token 往往强依赖最近几个词、代码行、工具返回片段。如果全部压缩,短程细节会丢失。
可以把 SWA 理解为:近处用高清,远处用压缩记忆。
5.3 CSA:压缩后再稀疏选择
Section titled “5.3 CSA:压缩后再稀疏选择”CSA, Compressed Sparse Attention,有两步:
- Compression:每
m个 token 的 KV 被压缩成一个 entry。V4 中m=4。 - Sparse selection:Lightning Indexer 给 compressed KV blocks 打分,然后选择 top-k 做主注意力。V4-Flash top-k 为 512,V4-Pro top-k 为 1024。
这相当于把长上下文变成一个“压缩记忆库”,当前 query 不再全量读取,而是先检索出相关压缩块。
研究上可以类比为:
full attention: query attends to all past tokensCSA: query retrieves relevant compressed memory blocksCSA 的精妙点在于,它不是只做静态稀疏模式,而是有 query-dependent selection。不同 query 会选择不同 compressed KV blocks。
5.4 HCA:更重压缩的全局背景
Section titled “5.4 HCA:更重压缩的全局背景”HCA, Heavily Compressed Attention,每 m'=128 个 token 压缩成一个 KV entry,但不做稀疏选择,而是保留更全局的 compressed dense attention。
它牺牲细节,换取全局覆盖。适合保存远程主题、文档结构、长期背景信息。
和 CSA 的区别:
| 模块 | 压缩率 | 是否稀疏选择 | 功能 |
|---|---|---|---|
| SWA | 不压缩 | 固定最近窗口 | 保留局部细节 |
| CSA | m=4 | top-k | 选择性读取相关历史 |
| HCA | m'=128 | 不稀疏选择 | 保留远程全局摘要 |
5.5 为什么 CSA + HCA 要混合?
Section titled “5.5 为什么 CSA + HCA 要混合?”只用 CSA,可能丢掉一些全局背景,因为 top-k selector 有召回风险。
只用 HCA,远程信息太粗,细粒度证据可能不够。
只用 SWA,无法覆盖长程信息。
所以 V4 采用 hybrid attention:局部细节、可选择记忆、全局摘要同时存在。
这其实是一个 memory hierarchy:
L1: SWA local exact memoryL2: CSA compressed selective memoryL3: HCA heavily compressed global memory6. mHC:给 residual stream 增加稳定的表达宽度
Section titled “6. mHC:给 residual stream 增加稳定的表达宽度”mHC, Manifold-Constrained Hyper-Connections,是 V4 的第二个重要架构创新。
普通 residual connection 基本是:
x_{l+1} = x_l + F_l(x_l)Hyper-Connections 的思想是把 residual stream 扩成 n_hc × d,让层与层之间不只是单一路径传递,而是在更宽的残差状态中做 mixing。这样可以给模型一个新的 scaling axis:不一定只靠增大 hidden size 或层数,也可以增大 residual stream 的表达空间。
问题是,naive HC 在深层堆叠时容易数值不稳定。mHC 的做法是把 residual mapping B_l 约束到 doubly stochastic matrix manifold,即 Birkhoff polytope:
- 行和为 1。
- 列和为 1。
- 元素非负。
这个约束带来的好处是 spectral norm 被控制在不超过 1,残差传播变成 non-expansive,不容易层层放大。
直观理解:
普通 HC:更多残差通道,但 mixing 可能失控mHC:更多残差通道,同时把 mixing 限制在稳定流形上它的工程代价是额外计算和 activation/通信开销,因此论文又专门设计 fused kernels、recomputation 和 pipeline overlap,把 mHC 的 wall-time overhead 控制在可接受范围。
7. Muon:V4 的优化器选择
Section titled “7. Muon:V4 的优化器选择”V4 对多数矩阵参数使用 Muon,对 embedding、prediction head、RMSNorm 权重、mHC 的部分静态参数等仍使用 AdamW。
Muon 的关键是对梯度更新做近似正交化。论文中使用 hybrid Newton-Schulz iterations:
- 前 8 步用一组系数快速把奇异值推近 1。
- 后 2 步换成更稳定的系数,把奇异值稳定在 1 附近。
为什么这对大模型重要?
- 大规模矩阵更新容易造成方向过度耦合。
- MoE 和长上下文注意力引入更多不稳定源。
- 正交化更新可能让训练更稳定、收敛更快。
但 Muon 也带来工程挑战:它需要完整矩阵做更新,不像 AdamW 那样天然适合 ZeRO 的元素级切分。因此 V4 设计了 hybrid ZeRO bucket assignment、矩阵合并、BF16 梯度同步等工程方案。
我的判断:Muon 在 V4 里不只是“换优化器”,而是与 mHC、MoE、长上下文训练稳定性绑定在一起。它是 V4 训练可行性的组成部分。
8. 低精度与 KV cache:成本优势的真正来源
Section titled “8. 低精度与 KV cache:成本优势的真正来源”V4 的效率不是只靠 CSA/HCA。论文中还叠加了多层低精度优化:
- KV cache 的 RoPE 维度用 BF16,其余维度用 FP8。
- CSA lightning indexer 的 attention computation 用 FP4。
- MoE expert weights 用 FP4 QAT。
- index scores 从 FP32 量化到 BF16,使 top-k selector 有约 2× 加速,并保持 99.7% KV recall。
V4 在 1M context 下的对比:
- V4-Pro 相比 DeepSeek-V3.2:约 27% single-token FLOPs,约 10% KV cache。
- V4-Flash 相比 DeepSeek-V3.2:约 10% single-token FLOPs,约 7% KV cache。
- 相比普通 BF16 GQA8 baseline,KV cache 可降到约 2% 级别。
这些数字说明 V4 的目标不是“benchmark 上能跑一次 1M”,而是把 1M 变成常规服务能力。
9. 训练设置:4K 到 1M 的课程学习
Section titled “9. 训练设置:4K 到 1M 的课程学习”V4 的训练数据超过 32T tokens:
- V4-Flash:32T tokens。
- V4-Pro:33T tokens。
- 数据强调数学、代码、网页、多语言、长文档、科学论文、技术报告。
- 中期训练加入 agentic data 增强 coding/agent 能力。
上下文长度课程:
4K -> 16K -> 64K -> 1M稀疏注意力不是一开始就上,而是:
- 先用 dense attention warmup。
- 到 64K 阶段引入 sparse attention。
- 先 warm up CSA lightning indexer。
- 再长期使用 sparse attention 训练。
这是非常实际的训练策略。因为如果 indexer 还不会选 memory blocks,过早启用稀疏注意力会让模型学习信号不稳定。
10. 训练不稳定:论文最诚实、也最有价值的部分之一
Section titled “10. 训练不稳定:论文最诚实、也最有价值的部分之一”V4 是 trillion-parameter MoE,训练不稳定不可避免。论文指出 loss spikes 与 MoE layer outliers、routing 机制相关。
他们用了两个实用技巧:
10.1 Anticipatory Routing
Section titled “10.1 Anticipatory Routing”在 step t:
- backbone 用当前参数
theta_t计算特征。 - routing indices 用历史参数
theta_{t-Δt}预先计算。
直观理解:把路由决策和主干网络同步更新解耦,避免 routing 与特征分布互相追逐造成振荡。
工程上,为了不每步付出巨大代价,他们只在检测到 loss spike 后触发短期 rollback + anticipatory routing,恢复稳定后回到普通训练。
10.2 SwiGLU Clamping
Section titled “10.2 SwiGLU Clamping”V4 对 SwiGLU 做数值截断:
- linear component clamp 到
[-10, 10]。 - gate component 上界 clamp 到
10。
这可以抑制 outliers,帮助稳定 MoE 训练。
需要注意:论文自己也承认,这两个技巧的底层理论还没完全搞清楚。它们是有效工程解,而不是已经完全解释的理论解。
11. 系统工程:这篇论文不是只讲模型结构
Section titled “11. 系统工程:这篇论文不是只讲模型结构”V4 的系统工程部分很重,原因很简单:百万上下文 + MoE + OPD + Agent rollout,不靠系统优化跑不动。
11.1 Fine-grained EP overlap
Section titled “11.1 Fine-grained EP overlap”MoE 的 expert parallelism 需要大量 dispatch/combine 通信。V4 把 MoE layer 分为:
- Dispatch。
- Linear-1。
- Activation。
- Linear-2。
- Combine。
它们把专家切成 waves,通信、计算、激活、combine 形成流水线。论文称:
- 一般 inference workload 相比强 non-fused baseline 有 1.50 到 1.73× speedup。
- RL rollout / 高速 agent serving 等 latency-sensitive 场景最高 1.96×。
核心观点是:通信是否瓶颈不只取决于带宽,而取决于 compute/communication ratio。只要通信能藏在计算下面,继续堆带宽的收益会递减。
11.2 TileLang
Section titled “11.2 TileLang”V4 架构包含很多定制算子,如果全靠 PyTorch ATen 拼接,会有大量小 kernel 调用和低效 tensor 操作。TileLang 的作用是:
- 快速开发 fused kernels。
- 降低 host-side invocation overhead。
- 用 Z3 做整数表达式分析,帮助优化 tensor index。
- 保证数值精度与 bitwise reproducibility。
对研究团队来说,这说明下一代 LLM 架构创新越来越依赖 kernel DSL 和编译器能力。
11.3 Batch-invariant / deterministic kernels
Section titled “11.3 Batch-invariant / deterministic kernels”V4 强调 batch invariance 和 determinism:
- 同一个 token 输出不应因 batch 位置不同而 bitwise 改变。
- 训练异常时可复现,有利于 debug loss spikes 和硬件问题。
- 后训练和推理行为保持一致。
这是工业级大模型训练很重要但常被论文轻描淡写的部分。V4 把它写出来,说明 DeepSeek 在大规模训练迭代里已经把“可复现性”当成生产力问题。
11.4 KV cache 管理与 on-disk cache
Section titled “11.4 KV cache 管理与 on-disk cache”CSA/HCA/SWA 让 KV cache 类型变得异构:
- CSA compressed KV。
- CSA indexer KV。
- HCA compressed KV。
- SWA uncompressed KV。
- 尚未凑够 compression block 的 tail states。
这破坏了传统 PagedAttention 的简单假设,所以 V4 设计:
- state cache 管理 SWA 和 tail uncompressed states。
- classical KV cache 管理 CSA/HCA compressed blocks。
- on-disk KV cache 存储共享 prefix,减少重复 prefill。
这对 Agent 和长文档场景很关键:大量请求会共享系统提示、工具 schema、文档前缀、历史上下文,能否复用 prefix KV 直接影响服务成本。
12. 后训练:从混合 RL 转向 OPD
Section titled “12. 后训练:从混合 RL 转向 OPD”V4 后训练有一个重要变化:把 DeepSeek-V3.2 中的 mixed RL stage 替换为 OPD。
整体流程:
- 各领域专家独立训练。
- 每个专家先 SFT,再用 GRPO 做 RL。
- hard-to-verify 任务用 GRM, Generative Reward Model。
- 最后用 multi-teacher OPD 合并到统一模型。
12.1 Reasoning effort 三模式
Section titled “12.1 Reasoning effort 三模式”V4 支持:
- Non-think:快速、直觉式、低成本。
- Think High:复杂任务,较长推理。
- Think Max:最大推理努力,用更长上下文和更少长度惩罚探索边界。
评估中:
- Non-think 使用 8K context。
- High 使用 128K context。
- Max 使用 384K context。
- Agent 任务常设最大 512K context 与最多 500 步工具交互。
这说明 V4 把 reasoning mode 当成产品与训练目标的一部分,而不是只靠 prompt 临时诱导。
12.2 GRM:让模型自己成为评判器
Section titled “12.2 GRM:让模型自己成为评判器”V4 对 hard-to-verify 任务不再主要依赖传统 scalar reward model,而是用 rubric-guided data + Generative Reward Model,让 actor model 本身具备评判能力。
这背后的思想是:
- 模型生成能力与评判能力共享推理结构。
- 对复杂任务,生成式评价比单个标量 reward 更能表达理由。
- 少量多样人类标注通过 rubric 泛化到更多复杂样本。
风险也很清楚:GRM 可能被策略模型 reward hacking,或者在开放任务中偏向某种风格。因此需要 rubric、人工评审和过程校验配合。
12.3 OPD:统一专家能力的关键
Section titled “12.3 OPD:统一专家能力的关键”OPD, On-Policy Distillation 的形式是:
student 在自己的轨迹上学习 teacher 分布loss = sum_i w_i * D_KL(pi_student || pi_teacher_i)V4 采用 full-vocabulary logit distillation,而不是只在采样 token 上估计 KL。原因是 token-level KL estimate 方差大、训练不稳定,而 full-vocab logits 更稳定、更忠实。
工程难点是 vocabulary 超过 100K,多 teacher logits 物化成本太高。V4 的解法:
- teacher weights offload 到集中式分布存储。
- teacher forward 时只缓存最后一层 hidden states。
- 训练时再通过对应 prediction head 重构 logits。
- 同一个 mini-batch 尽量按 teacher index 排序,让每次只加载一个 teacher head。
- 用 TileLang kernel 算 exact KL。
我的判断:OPD 是 V4 后训练中最重要的范式变化。它把“多专家系统”压缩成“一个统一模型”,避免在线 ensemble 的服务成本,也避免粗暴混合 RL 造成专家能力相互干扰。
13. Agent 与工具调用:V4 的产品化设计很明显
Section titled “13. Agent 与工具调用:V4 的产品化设计很明显”V4 不只是 benchmark 模型,它对 agent/chatbot 服务做了不少接口设计。
13.1 DSML 工具调用格式
Section titled “13.1 DSML 工具调用格式”V4 引入 |DSML| 特殊 token 和 XML-like 工具调用格式。论文说 XML 格式能减少 escaping failures 和 tool-call errors。
这反映一个趋势:模型工具调用格式越来越像编程语言/协议,而不是自由文本。
13.2 Interleaved Thinking
Section titled “13.2 Interleaved Thinking”V4 区分两种场景:
- 工具调用场景:保留完整 reasoning history,跨 user turns 也保留。
- 普通对话场景:新用户消息到来时丢弃旧 thinking,避免无谓膨胀。
这依赖 1M context。长工具任务里,如果每轮都丢掉推理轨迹,模型会反复重建状态;V4 选择在 agent 场景保留轨迹,用上下文长度换任务连续性。
13.3 Quick Instruction
Section titled “13.3 Quick Instruction”V4 用特殊 tokens 处理搜索触发、query 生成、标题生成、domain 判断等辅助任务,复用已有 KV cache,避免再跑一个小模型做 intent classifier。
这很工程化:不是所有小任务都值得独立模型服务,很多可以作为同一个大模型上下文里的 quick head/task token。
14. 评估结果怎么读?
Section titled “14. 评估结果怎么读?”14.1 Base 模型
Section titled “14.1 Base 模型”Base 阶段,V4-Pro-Base 在大多数 benchmark 上超过 V4-Flash-Base 和 V3.2-Base。几个关键数字:
- LongBench-V2:V3.2-Base 40.2,V4-Flash-Base 44.7,V4-Pro-Base 51.5。
- Simple-QA verified:V3.2-Base 28.3,V4-Flash-Base 30.1,V4-Pro-Base 55.2。
- MMLU-Pro:V3.2-Base 65.5,V4-Flash-Base 68.3,V4-Pro-Base 73.5。
解读:
- V4-Pro 的大参数规模带来明显知识优势。
- V4-Flash 用更少激活参数仍能超过 V3.2-Base,说明架构/数据/训练优化有效。
- 长上下文能力从 base 阶段就已经显著提升。
14.2 Pro-Max 与外部模型对比
Section titled “14.2 Pro-Max 与外部模型对比”论文 Table 6 中 DeepSeek-V4-Pro-Max:
- SimpleQA-Verified:57.9,超过 GPT-5.4 45.3 和 Opus-4.6 46.2,但低于 Gemini-3.1-Pro 75.6。
- Codeforces rating:3206,高于 GPT-5.4 的 3168 和 Gemini-3.1-Pro 的 3052。
- LiveCodeBench:93.5,高于 Gemini-3.1-Pro 91.7。
- MRCR 1M:83.5,低于 Opus-4.6 92.9,高于 Gemini-3.1-Pro 76.3。
- SWE Verified:80.6,与 Gemini-3.1-Pro 80.6 持平,略低于 Opus-4.6 80.8。
- Toolathlon:51.8,低于 GPT-5.4 54.6,高于 Gemini-3.1-Pro 48.8。
解读:
- V4 在代码竞赛、长上下文、开放模型知识能力上非常强。
- 在部分知识和 agent benchmark 上已接近或局部超过 closed frontier。
- 但并非全面领先,尤其 Gemini 在某些知识评估上仍明显更强。
14.3 Reasoning effort 的意义
Section titled “14.3 Reasoning effort 的意义”Table 7 显示 Max 模式在困难任务上显著提升。例如:
- V4-Pro HLE:Non-think 7.7,High 34.5,Max 37.7。
- V4-Pro Codeforces:High 2919,Max 3206。
- V4-Pro MRCR 1M:High 83.3,Max 83.5,提升很小。
这说明:
- 对数学、代码、复杂推理,test-time scaling 很有效。
- 对长上下文检索,更多 thinking 不一定显著提升,瓶颈可能在 retrieval/attention recall。
- Flash 与 Pro 的差距在知识任务更大,在推理任务可通过更多 token 缩小。
15. 真实任务:V4 想覆盖的不只是 benchmark
Section titled “15. 真实任务:V4 想覆盖的不只是 benchmark”论文的 real-world tasks 部分值得看,因为它暴露了 V4 的产品目标。
15.1 中文写作
Section titled “15.1 中文写作”V4-Pro 在中文功能写作中相对 Gemini-3.1-Pro 总胜率 62.7% vs 34.1%。创意写作中:
- instruction following win rate 60.0%。
- writing quality win rate 77.5%。
但在最难的高复杂约束、多轮场景里,Claude Opus 4.5 仍有优势。
15.2 Search
Section titled “15.2 Search”V4 区分:
- Non-think:RAG。
- Thinking mode:agentic search。
论文认为 agentic search 在复杂任务上明显优于 RAG,且成本只略高。这和 1M context + tool thinking 的主线一致。
15.3 白领任务与代码 Agent
Section titled “15.3 白领任务与代码 Agent”V4-Pro-Max 在 30 个中文高级办公任务中对 Opus-4.6-Max 非败率 63%。
内部 R&D Coding benchmark 中,V4-Pro-Max pass rate 67%,接近 Opus 4.5 的 70%,低于 Opus 4.6 Thinking 的 80%。
这说明 V4 的 Agent 能力已能进入高价值生产场景,但在复杂指令细节、摘要压缩、幻灯片审美和模糊需求理解上仍有短板。
16. 与多模态论文的关系
Section titled “16. 与多模态论文的关系”你后面要看的 Thinking with Visual Primitives 其实可以看成 V4 技术栈的多模态延伸。
V4 提供:
- 高效长上下文。
- 低 KV cache 成本。
- MoE 高容量。
- OPD 合并专家能力。
- Agent/工具/长推理接口。
多模态论文在此基础上加:
- DeepSeek-ViT。
- 视觉 token 压缩。
- box/point visual primitives。
- 多模态视觉推理专家训练。
所以先理解 V4 很有必要。V4 是地基,多模态论文是把视觉推理能力接到这套地基上。
17. 这篇论文真正的研究贡献
Section titled “17. 这篇论文真正的研究贡献”我把贡献分成四层:
17.1 架构贡献
Section titled “17.1 架构贡献”CSA + HCA + SWA 构成长上下文 memory hierarchy,使 1M context 从理论窗口变成可服务窗口。
17.2 稳定性贡献
Section titled “17.2 稳定性贡献”mHC、Muon、Anticipatory Routing、SwiGLU Clamping 共同解决深层 MoE 训练稳定性。尤其 Anticipatory Routing 暴露了 MoE routing 与 outliers 的耦合问题,这是后续研究很值得深入的点。
17.3 工程贡献
Section titled “17.3 工程贡献”MegaMoE、TileLang、deterministic kernels、KV cache layout、on-disk cache、FP4 QAT,把模型架构转成可部署系统。
17.4 后训练贡献
Section titled “17.4 后训练贡献”OPD 替代 mixed RL,把多个领域专家整合到统一模型里。这个范式可能会成为未来大模型后训练的重要方向。
18. 我对 V4 的审慎评价
Section titled “18. 我对 V4 的审慎评价”- 长上下文效率是实打实的主线,不是仅扩大窗口。
- Flash/Pro 双模型设计兼顾成本和能力。
- OPD 管线很有战略价值,尤其适合多专家能力快速迭代。
- 系统工程披露充分,能看到实际生产级约束。
- 对 Agent 和真实任务的考虑比很多纯 benchmark 论文更深入。
需要谨慎的地方
Section titled “需要谨慎的地方”- 架构复杂度很高,论文自己也承认未来要 distill 到更 essential 的设计。
- Anticipatory Routing 和 SwiGLU Clamping 有效但理论解释不足。
- 很多 benchmark 是 internal 或 proprietary evaluation,需要外部复现。
- 1M context 在 MRCR 上超过 128K 后仍有退化,说明 retrieval/recall 仍未完全解决。
- OPD 的 teacher 权重、数据调度、full-vocab KL 工程成本极高,普通团队不容易复现。
- Max reasoning 的能力提升依赖更多推理 token,成本、延迟和可控性仍是产品挑战。
19. 如果你是研究者,下一步该怎么读?
Section titled “19. 如果你是研究者,下一步该怎么读?”建议按这个顺序读:
-
先读 Introduction + Figure 1
- 明确 V4 想解决的是 test-time scaling 的效率瓶颈。
-
重点读 2.3 Hybrid Attention
- CSA/HCA 是论文中心。
- 把 SWA、CSA、HCA 看成三层 memory hierarchy。
-
读 2.2 mHC 和 2.4 Muon
- 理解它为什么不仅是 attention 论文,也是在解决深层 MoE 训练稳定性。
-
读 3.6 Inference Framework
- 看懂异构 KV cache 与 on-disk cache,才能理解它为什么能服务 1M context。
-
读 5.1/5.2 Post-Training + OPD
- 这是 V4 能力合并的关键。
-
最后读 Evaluation
- 不要只看平均强弱,要看哪些任务吃 reasoning tokens,哪些任务吃知识规模,哪些任务吃长上下文 recall。
20. 给团队的落地启示
Section titled “20. 给团队的落地启示”如果一个团队想借鉴 V4,不建议一上来复刻完整系统。可以分层吸收:
- 小团队:学习 OPD / specialist training 思路,做领域专家蒸馏合并。
- 中型团队:尝试 sliding window + compressed memory + retrieval-style attention 的简化版本。
- 大型团队:关注 KV cache 管理、prefix cache、deterministic kernels、FP4/QAT。
- Agent 产品团队:重点学习 interleaved thinking、Quick Instruction、tool schema 和 long-context state management。
最重要的启示是:下一代模型竞争不是单点算法竞争,而是模型架构、训练稳定性、推理系统、后训练和产品接口共同优化。
21. 总结
Section titled “21. 总结”DeepSeek-V4 的核心不是“参数更大”,而是围绕一个判断展开:未来能力增长越来越依赖 test-time scaling,而 test-time scaling 需要高效长上下文作为基础设施。
为此,V4 做了四件事:
- 用 CSA + HCA + SWA 降低 1M context 的 attention 与 KV cache 成本。
- 用 mHC + Muon + routing/clamping 稳住深层 MoE 训练。
- 用 FP4/FP8、TileLang、MegaMoE、异构 KV cache 把架构变成可训练可服务系统。
- 用专家 SFT/RL + OPD 把数学、代码、Agent、指令能力合并到统一模型。
从大模型研究角度看,V4 很像一个分水岭:它把“长上下文”从窗口参数推进到系统范式,把“推理能力”从单模型训练推进到专家合并,把“模型论文”推进到模型-系统-产品接口一体化设计。它不完美,甚至有些复杂,但方向非常清楚:让百万上下文成为 test-time intelligence 的计算底座。