DeepSeek 视觉原语
This content is not available in your language yet.
日期:2026-05-01
视角:大模型/多模态模型研究与工程化落地
主论文:Thinking with Visual Primitives
关联底座论文:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
0. 资料与可信度说明
Section titled “0. 资料与可信度说明”我核验到的 DeepSeek “v4.0” 正式论文/技术报告是 DeepSeek-V4,标题为 DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence。它目前不是以 arXiv 页面为主入口,而是发布在 Hugging Face 的 DeepSeek-V4 系列仓库中:
- DeepSeek-V4-Pro 模型页与论文 PDF:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- DeepSeek-V4-Flash 模型页与论文 PDF:https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- V4 官方 collection:https://huggingface.co/collections/deepseek-ai/deepseek-v4
- 本地已下载备份:
analysis/sources/DeepSeek_V4.pdf
多模态论文来源:
- 用户提供本地 PDF:
Thinking_with_Visual_Primitives.pdf - 官方 GitHub 页面:https://github.com/deepseek-ai/Thinking-with-Visual-Primitives
- 本地正文抽取:
analysis/extracted/thinking_with_visual_primitives.txt
重要校正:用户说的 “DeepSeek v4.0” 在官方命名里是 DeepSeek-V4。这篇多模态论文的语言底座直接引用的是 DeepSeek-V4-Flash,所以找 V4 论文不是旁支材料,而是理解多模态模型 token 效率、长上下文能力、后训练范式的关键。
1. 两张核心讲解图
Section titled “1. 两张核心讲解图”图 1:视觉原语推理闭环
Section titled “图 1:视觉原语推理闭环”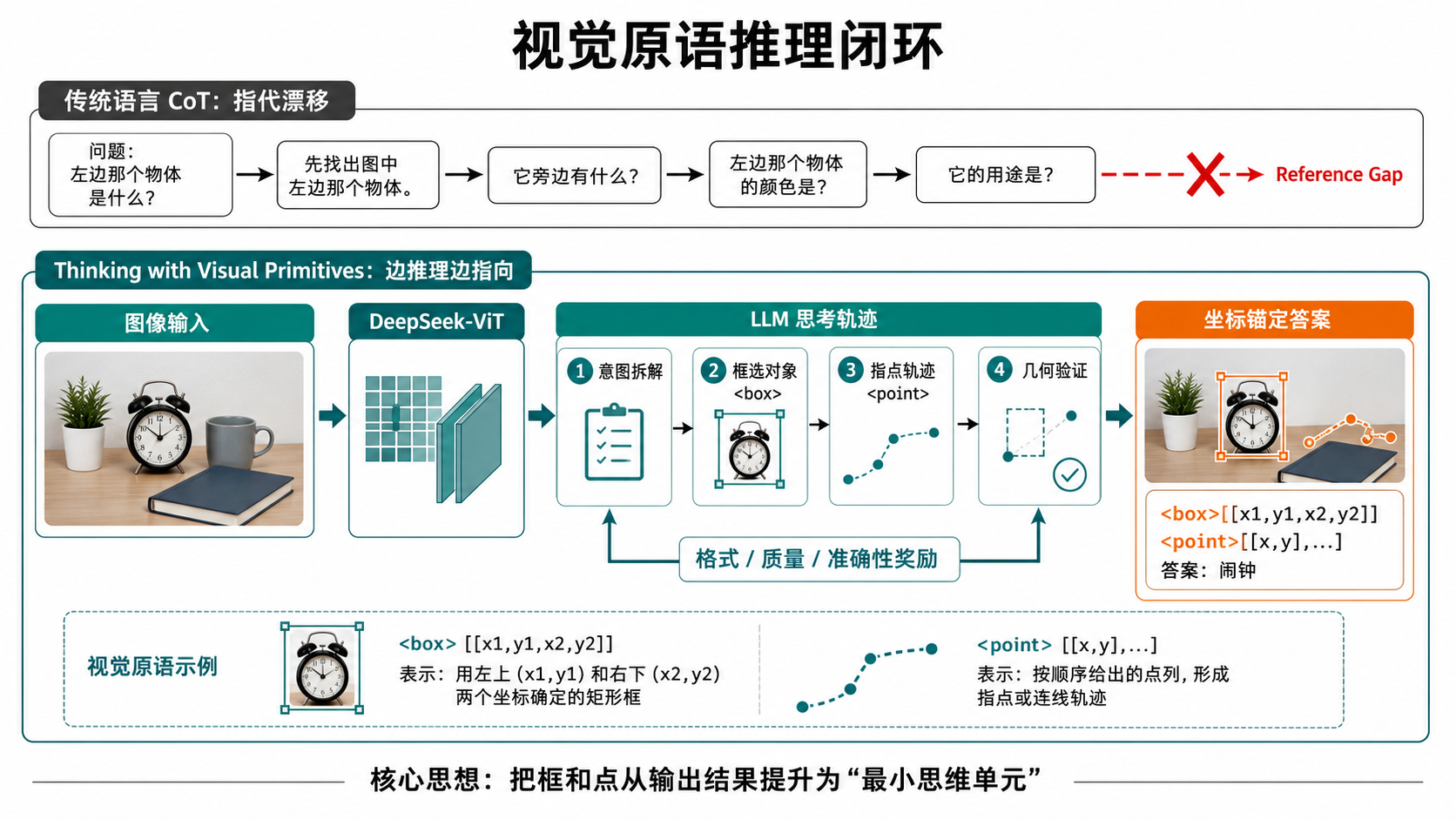
这张图解释主论文最核心的思想:传统多模态 CoT 主要在语言空间里说“左边那个”“旁边那个”,但这些自然语言指代很容易在复杂图像中漂移;Thinking with Visual Primitives 把框和点插入推理轨迹中,让模型在推理时显式绑定坐标。
图 2:DeepSeek-V4 到视觉原语模型的技术栈
Section titled “图 2:DeepSeek-V4 到视觉原语模型的技术栈”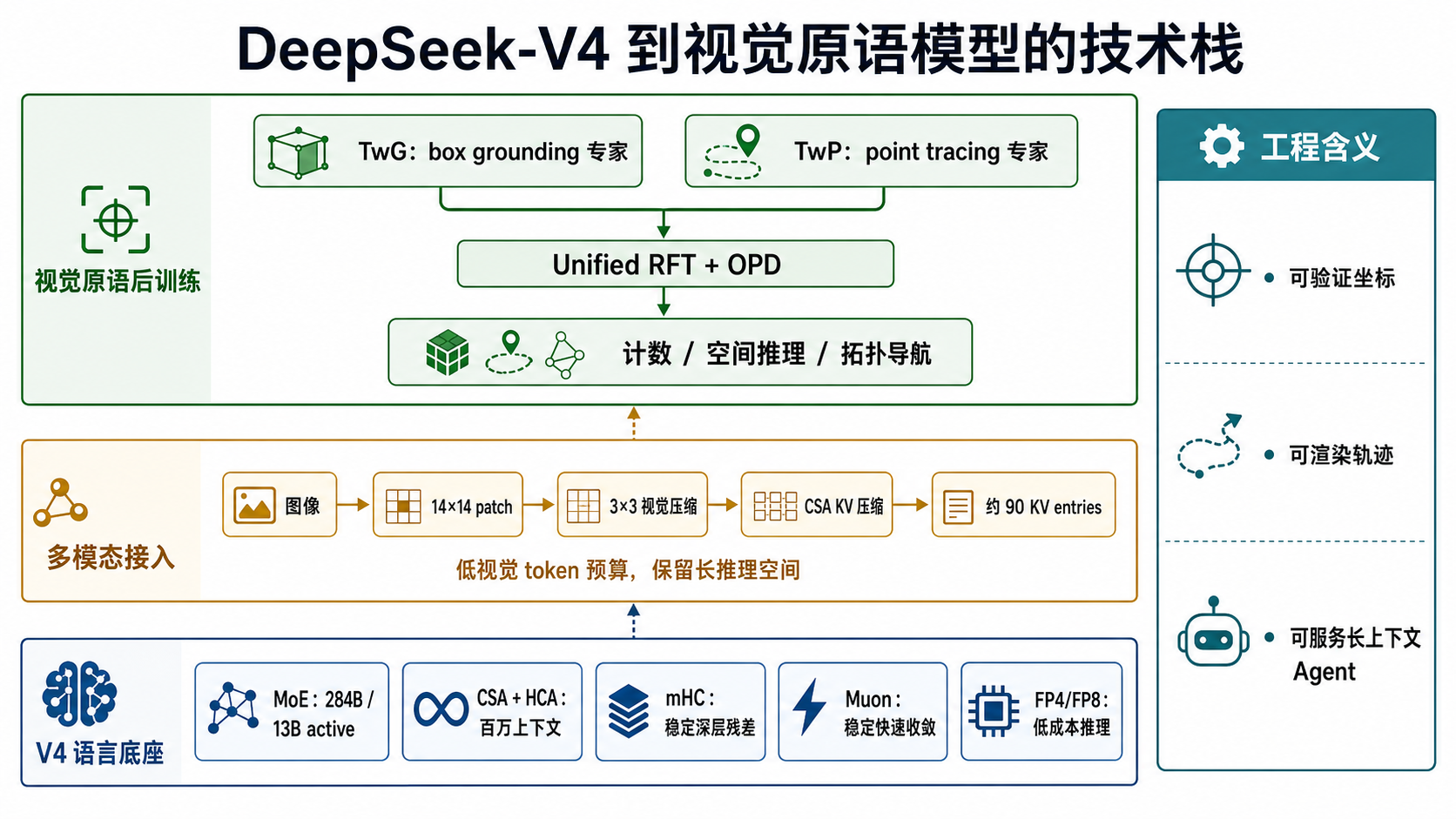
这张图解释主论文和 V4 技术报告之间的关系:V4-Flash 提供 MoE 语言底座、CSA/HCA 长上下文注意力、mHC 稳定训练、Muon 优化与低精度推理基础;多模态论文在其上接入 DeepSeek-ViT、视觉 token 压缩和视觉原语后训练。
2. 一句话读懂这篇论文
Section titled “2. 一句话读懂这篇论文”这篇论文的关键贡献不是“又做了一个更会看图的 VLM”,而是提出了一个更强的多模态推理接口:把视觉坐标原语,即 bounding box 和 point,从最终答案中的辅助输出,提升为推理过程中的最小思维单元。
论文把问题拆成两个 gap:
- Perception Gap:模型看不清细节。常见解法是更高分辨率、crop、dynamic patch、高视觉 token 预算。
- Reference Gap:模型即使看到了,也无法在语言推理过程中稳定指代“到底是哪一个对象/哪条路径/哪个位置”。这篇论文主攻的是这个 gap。
我的判断:这篇工作最值得重视的地方在于,它把多模态推理从“语言描述视觉”推进到“语言 + 坐标变量共同构成推理状态”。这是比单纯加大视觉 encoder 或图像分辨率更结构化的一步。
3. 核心问题:为什么自然语言 CoT 不够?
Section titled “3. 核心问题:为什么自然语言 CoT 不够?”在复杂视觉任务里,纯语言 CoT 的失败经常不是因为模型完全不知道图里有什么,而是因为中间推理状态里的指代对象失真。
典型例子:
- 计数任务里,模型说“我看到左边有三个,右边有两个”,但没有保存每个实例的身份,后续容易漏数或重复数。
- 空间推理里,模型说“灰色金属物体旁边的紫色橡胶物体”,但图像中可能有多个灰色、多个金属、多个相邻对象,语言描述不足以唯一绑定目标。
- 迷宫和路径追踪里,语言很难表达连续曲线、交叉点、回溯路径。模型说“往右上走再往左”,但没有坐标轨迹,拓扑状态不可验证。
论文称这类失败为 Reference Gap。从研究角度看,可以把它形式化为:
- 语言 token 中的指代表达
r_text需要映射到图像空间的区域/点r_image。 - 当图像里存在多个候选区域时,
P(r_image | r_text, image)的熵很高。 - 视觉原语把
r_image显式写成坐标变量,如<box>[[x1,y1,x2,y2]]</box>或<point>[[x,y],...]</point>,从而降低指代不确定性。
这相当于给多模态 CoT 加了一层“可渲染、可校验的变量绑定系统”。
4. Visual Primitives 到底是什么?
Section titled “4. Visual Primitives 到底是什么?”论文定义了两类视觉原语:
- Bounding boxes:适合对象定位、计数、属性比较、物体级空间关系。box 不仅提供中心位置,还提供尺度、范围、重叠关系和实例边界。
- Points:适合轨迹、路径、迷宫、曲线追踪、拓扑连通性。point 更轻量,适合表达序列化的空间动作。
输出协议采用特殊 token:
<|ref|>TARGET<|/ref|><|box|>[[x1,y1,x2,y2], ...]<|/box|><|point|>[[x1,y1],[x2,y2], ...]<|/point|>坐标被归一化到 0..999 的离散整数空间。这个设计很工程化:它不要求客户端知道原图像素大小,只需要把归一化坐标反投影到显示画布即可。
一个细节:PDF 文本抽取里 756×756 输入经过 14×14 patch 后是 2916 patch tokens,3×3 压缩后应为 18×18 = 324 个视觉 token;正文抽取显示为 3241,应是 324 后接脚注编号 1。再经过 CSA 的 KV 压缩后,KV cache 中约为 81 个视觉 KV entries。
5. 架构:LLaVA-like,但关键在极端视觉 token 效率
Section titled “5. 架构:LLaVA-like,但关键在极端视觉 token 效率”主论文的整体结构类似 LLaVA:
- 图像进入 DeepSeek-ViT。
- ViT 输出视觉 token。
- 视觉 token 与语言指令拼接。
- 输入 DeepSeek-V4-Flash 语言模型。
- 模型输出语言回答,并在思考轨迹中穿插 box/point。
但这篇论文真正的架构重点是 视觉 token 极度压缩后仍要保留推理能力:
- DeepSeek-ViT 使用
14×14patch。 - ViT 输出端做
3×3spatial token compression。 - V4-Flash 的 CSA 机制进一步把视觉 KV cache 压缩。
- 论文给出的 800×800 输入对比中,自家模型只保留约 90 个视觉 KV cache entries,却在选定视觉推理 benchmark 上达到 77.2 的平均分。
这和很多“多看一点图像 token”的路线不同。论文的假设是:如果模型能在推理过程中用坐标显式绑定对象,就不必完全依赖巨量视觉 token 来隐式记住所有空间关系。
6. DeepSeek-V4 论文对这篇多模态论文的意义
Section titled “6. DeepSeek-V4 论文对这篇多模态论文的意义”V4 技术报告给出了这篇多模态模型的基础能力来源。V4 系列包含:
- DeepSeek-V4-Pro:1.6T total parameters,49B activated。
- DeepSeek-V4-Flash:284B total parameters,13B activated。
- 两者都支持 1M token context。
- V4-Pro 在 1M token 场景下,相比 DeepSeek-V3.2 只需要约 27% 的单 token inference FLOPs 和约 10% 的 KV cache。
- V4-Flash 在 1M token 场景下进一步降到约 10% FLOPs 和约 7% KV cache。
V4 的关键技术点:
- CSA, Compressed Sparse Attention:先把每
m个 token 的 KV 压缩成一个 entry,再用 sparse selection 选 top-k compressed KV 做注意力。V4-Flash 中m=4,top-k 为 512。 - HCA, Heavily Compressed Attention:更激进的压缩,每
m'个 token 合成一个 entry,但保留 dense attention;V4 中m'=128。 - Hybrid CSA + HCA:CSA 保留可选择的细粒度长程信息,HCA 提供更强压缩的全局背景,两者交替使用。
- mHC, Manifold-Constrained Hyper-Connections:把 residual mapping 约束到 doubly stochastic matrix manifold,控制 spectral norm,提升深层堆叠稳定性。
- Muon optimizer:对大部分矩阵参数使用近似正交化更新,提升收敛和稳定性;embedding、prediction head、RMSNorm 等仍用 AdamW。
- FP4/FP8 与工程内核:MoE expert 权重、CSA indexer QK path 等用 FP4/QAT 或低精度路径,配套 TileLang、DeepGEMM、MegaMoE 等内核和推理框架。
- OPD, On-Policy Distillation:V4 后训练用多教师 on-policy distillation 合并专家能力,替代混合 RL 的一部分复杂性。
多模态论文直接继承了这些能力:
- 语言底座用 V4-Flash,所以 13B active 的 MoE 让推理成本相对可控。
- CSA 让视觉 token 的 KV cache 压缩成为可能。
- 1M/长上下文能力让模型能容纳更长的视觉轨迹、路径点、回溯过程。
- 后训练采用“专家训练再合并”的范式,和 V4 论文中的 OPD 思路高度一致。
7. 数据构造:这篇论文其实是数据工程驱动的
Section titled “7. 数据构造:这篇论文其实是数据工程驱动的”论文的数据部分非常重要。Visual primitives 不只是换一个输出格式,它需要让模型在大量任务中学会“什么时候框、框谁、框多少、如何用框继续推理”。
7.1 大规模 box grounding 数据
Section titled “7.1 大规模 box grounding 数据”论文爬取和整理了大规模 box grounding 数据:
- 初始获得 97,984 个 box-grounding-related data sources。
- 语义质量 review 后保留 43,141 个数据源。
- 视觉几何质量 review 后保留 31,701 个数据源。
- 类别均衡采样,最终得到超过 4000 万高质量样本。
两个过滤阶段值得关注:
- Semantic-based Review:过滤无意义机器码、私有实体、不可泛化标签、主观标签,例如
OK/NG。 - Visual-Geometric Quality Review:过滤严重漏标、严重偏移/截断、覆盖全图的 mega boxes。
研究判断:这说明 DeepSeek 很清楚 grounding 数据的主要风险不只是 box 坐标噪声,更是“标签是否具备自然语言语义”。如果标签不可泛化,模型会学到对视觉语言对齐有害的映射。
7.2 为什么优先扩大 box,而不是 point?
Section titled “7.2 为什么优先扩大 box,而不是 point?”论文给出三点理由:
- box 更确定,point 的 ground truth 有内在歧义。
- box 可退化成 point,因为一个框由两个点定义,中心点也可派生。
- box 信息量更高,包含位置、尺度、几何范围。
这是合理的。Point 更适合轨迹类任务,但如果预训练阶段大规模 point 标注不稳定,会把噪声直接注入坐标 token 分布。
7.3 Cold-start 数据
Section titled “7.3 Cold-start 数据”后训练需要高精度 cold-start data。论文构造了四类:
- Counting:约 10,000 样本。粗粒度计数用 batch grounding,一次框出所有候选;细粒度计数用逐个扫描与属性验证,并加入零答案负例。
- Spatial Reasoning & General VQA:约 9,000 样本。自然图像基于 GQA,合成场景基于 CLEVR,并利用 execution trace 投影到 2D box。
- Maze Navigation:约 460,000 样本。用 DFS、Prim、Kruskal 生成矩形、圆形、蜂窝拓扑迷宫,包含可解与不可解样本。
- Path Tracing:约 125,000 样本。用 Bézier 曲线生成交叉路径,要求模型沿曲线输出点序列并识别终点。
我的判断:这四类任务不是随便选的。它们分别覆盖了视觉原语的四种推理压力:
- 实例绑定:计数。
- 多跳关系绑定:空间推理。
- 连通性搜索:迷宫。
- 局部几何连续性:曲线追踪。
8. 后训练:先专家化,再统一
Section titled “8. 后训练:先专家化,再统一”论文的 post-training pipeline 是:
-
Specialized SFT
- 数据配比为 70% general multimodal / pure-text,30% visual-primitives specialized data。
- box 和 point 分开训练,得到
FTwG和FTwP。 - 分开训练是为了避免小规模 specialized data 下的模式冲突。
-
Specialized RL
- 分别对
FTwG和FTwP做 GRPO。 - RL 阶段不显式监督中间 visual primitives,只需要 image、question、final answer,从而扩大可用数据。
- Reward 分三类:format、quality、accuracy。
- 分别对
-
Unified RFT
- 用专家模型 rollout 数据。
- 保留 Normal-Level 样本,随机保留 5% Easy-Level 防止简单场景遗忘。
- 从 base pretrained model 初始化,训练统一模型
F。
-
On-Policy Distillation
- 用
ETwG和ETwP作为 teacher。 - 让 student 在自己的生成轨迹上对齐 teacher 分布。
- 使用 full-vocabulary logit distillation。
- 用
关键点是:**中间坐标不一定在 RL 阶段被逐 token 监督,而是通过最终答案和可验证 reward 间接塑形。**这降低了数据成本,但也意味着中间轨迹有可能出现“看似合理但非因果”的风险,因此 rule-based verifier 的设计非常重要。
9. Reward 设计的研究价值
Section titled “9. Reward 设计的研究价值”这篇论文的 reward 设计比普通 VQA 更接近“视觉程序执行验证”。
9.1 Counting reward
Section titled “9.1 Counting reward”计数使用相对误差的指数衰减:
R(y_hat, y) = alpha * exp(-beta * |y_hat - y| / (|y| + 1))论文中 alpha=0.7, beta=3。它不是二元 exact match,而是给接近正确的答案提供平滑信号。对密集计数来说,这是更稳定的,因为误差 1 和误差 20 不该同等惩罚。
9.2 Maze reward
Section titled “9.2 Maze reward”Maze reward 拆为:
- causal exploration progress
- exploration completeness
- wall violation penalty
- final path validity
- answer correctness
这个设计很有价值:如果模型早期走穿墙,后续探索被截断,因为因果上已经无效。它不是只看最终 True/False,而是奖励每一步合法的空间推理。
9.3 Path tracing reward
Section titled “9.3 Path tracing reward”Path tracing 使用双向轨迹对齐:
- predicted points 到 ground-truth curve 的距离。
- ground-truth points 到 predicted polyline 的距离。
双向评价很关键。只做前向,模型可以只输出靠近起点的少量安全点;只做反向,模型可以绕远路覆盖曲线但加入幻觉 detour。双向约束逼迫模型输出完整且准确的轨迹。
10. 实验结果怎么读?
Section titled “10. 实验结果怎么读?”论文评估包含公共 benchmark 和自建 in-house benchmark。模型对比包括 Gemini-3-Flash、GPT-5.4、Claude-Sonnet-4.6、Gemma4-31B、Qwen3-VL-235B-A22B-Thinking,以及自家 Ours-284B-A13B-Thinking。
10.1 计数
Section titled “10.1 计数”- CountQA:Gemini-3-Flash
66.1/75.1,Ours64.9/74.1,略低于 Gemini。 - Pixmo-Count:Ours
89.2,高于 Gemini88.2。 - DS_Finegrained_Counting:Ours
88.7,高于 Qwen3-VL87.2和 GPT-5.484.2。
解读:公开计数上不是全面碾压,但在细粒度、自建高质量计数任务上优势明显。这符合方法特点:box 对实例绑定和属性过滤帮助最大。
10.2 空间推理与一般 VQA
Section titled “10.2 空间推理与一般 VQA”- MIHBench:Ours
85.3,最高。 - SpatialMQA:Ours
69.4,最高。 - EmbSpatial:Ours 与 Qwen3-VL 同为
83.7。 - CV-Bench:Gemini
88.6,Ours88.4,接近但不是最高。 - OmniSpatial:Gemini
59.6,Ours59.5,几乎持平。 - DS_Spatial_Reasoning:Ours
98.7,最高。
解读:视觉原语对 multi-hop spatial reasoning 的增益更突出;对泛化型 VQA,它更像增强器,不一定替代更强的通用视觉语言能力。
10.3 拓扑推理是最大亮点
Section titled “10.3 拓扑推理是最大亮点”- DS_Maze_Navigation:Ours
66.9,其他模型大多约49-51。 - DS_Path_Tracing:Ours
56.7,GPT-5.446.5,Gemini41.4,Claude30.6。
解读:这是论文最有说服力的结果。迷宫和路径追踪需要显式空间状态,传统语言 CoT 很难稳定表达。Point 序列成为“可执行轨迹”,所以模型明显受益。
10.4 Token efficiency
Section titled “10.4 Token efficiency”论文 Figure 1 强调:在 800×800 图像上,Ours 约 361 tokens / 约 90 KV cache entries,而一些 frontier 模型需要更多视觉 token。它在选定的 7 个 benchmark 上平均 77.2。
需要谨慎:论文也明确说,这个平均分只覆盖与研究主题相关的子集,不能代表模型整体能力。
11. 这篇论文的理论贡献
Section titled “11. 这篇论文的理论贡献”我认为可从五个角度理解。
11.1 从“语言链”到“带类型变量的推理链”
Section titled “11.1 从“语言链”到“带类型变量的推理链””传统 CoT 是纯 token 序列。Visual-primitives CoT 则像给推理链引入了 typed variables:
<box>是对象变量。<point>是位置/轨迹变量。- 语言说明是对变量的解释和操作。
这让多模态推理更接近程序执行:先绑定变量,再对变量做计数、比较、连通性搜索。
11.2 坐标是外部化工作记忆
Section titled “11.2 坐标是外部化工作记忆”人类在数东西或走迷宫时会用手指、眼动、标记点。论文把这个机制类比为 deictic pointers。坐标 token 在模型生成中扮演类似“外部工作记忆”的角色:
- 防止重复计数。
- 防止对象身份漂移。
- 记录已探索路径。
- 给后续步骤提供可引用状态。
11.3 可验证中间过程
Section titled “11.3 可验证中间过程”视觉原语让中间推理过程可以被 overlay 和 rule-based checker 检查。相比自然语言解释,坐标有更强的自动验证属性:
- box 是否重复?
- point 是否穿墙?
- path 是否连续?
- endpoint 是否到达?
- count 是否等于 box 数量?
这为 RL 提供了高质量 dense reward,是这篇论文能做起来的关键。
11.4 视觉原语是弱形式的“神经-符号接口”
Section titled “11.4 视觉原语是弱形式的“神经-符号接口””它不是完整的符号系统,但已经把连续视觉输入离散成可操作变量。可以理解为:
image features -> coordinate primitives -> language reasoning -> verifier / answer这比纯端到端黑盒 VQA 更容易工程化,也更利于调试。
11.5 它没有解决所有视觉推理问题
Section titled “11.5 它没有解决所有视觉推理问题”视觉原语主要解决 reference 和 spatial state tracking。它不能自动解决:
- 图像细节看不清。
- OCR 小字识别失败。
- 复杂视觉属性判断错误。
- 坐标框住了目标但语义分类错。
- point 轨迹在跨域真实场景中泛化不足。
所以它应该和 high-resolution perception、region crop、tool-based vision pipelines 结合,而不是替代它们。
12. 工程化视角:如果要落地,最重要的是什么?
Section titled “12. 工程化视角:如果要落地,最重要的是什么?”12.1 输出协议要稳定
Section titled “12.1 输出协议要稳定”实际产品中,必须把 <box>、<point> 输出作为 schema 处理,而不能只当文本:
- 解析失败要重试或修复。
- 坐标要 clamp 到
0..999。 - 多图输入要区分 image id。
- overlay 渲染要与 resize/crop 流程一致。
- 点序列要做简化、平滑和连通性检查。
12.2 不建议直接暴露完整 CoT
Section titled “12.2 不建议直接暴露完整 CoT”论文里展示了长 thinking content,但产品化时要小心:
- 长 CoT 消耗 token。
- 可能泄露内部推理细节。
- 用户不一定需要完整思维链。
更实用的接口可能是:
{ "answer": "...", "visual_primitives": [ {"type": "box", "label": "target", "coords": [x1, y1, x2, y2]}, {"type": "point_path", "label": "route", "coords": [[x, y], ...]} ], "short_rationale": "..."}12.3 UI/Agent 场景很适合
Section titled “12.3 UI/Agent 场景很适合”这类方法天然适合:
- GUI agent:点击、拖拽、定位控件。
- 文档/表格视觉分析:框选单元格、区域、图表元素。
- 工业检测:框选缺陷并解释。
- 医疗影像辅助:区域 grounding + 不确定性提示。
- 机器人/具身智能:point trajectory 转动作路径。
- 教育/解题:在几何图、迷宫、复杂图示上展示推理轨迹。
12.4 需要检测“坐标幻觉”
Section titled “12.4 需要检测“坐标幻觉””坐标输出看起来精确,但不保证正确。落地必须加二级校验:
- box 与检测器/segmenter 交叉验证。
- path 与图像拓扑算法交叉验证。
- 计数答案与 box 数量一致性检查。
- 对低置信区域触发 crop-and-reason。
12.5 数据工程是壁垒
Section titled “12.5 数据工程是壁垒”论文中 4000 万级 grounding 样本、46 万 maze、12.5 万 path tracing,不是小规模 prompt trick。要复现类似能力,最大成本在:
- 数据清洗。
- 标注协议统一。
- 程序化生成。
- verifier 设计。
- rollout difficulty mining。
- 专家模型合并。
13. 与 DeepSeek-V4 后训练范式的关系
Section titled “13. 与 DeepSeek-V4 后训练范式的关系”V4 技术报告中,DeepSeek 把后训练重点放在 specialist training + OPD:
- 先训练多个领域专家。
- 再通过 full-vocabulary OPD 合并到统一模型。
- 避免简单权重合并或混合 RL 的能力互相干扰。
多模态论文几乎沿用了这个思想:
ETwG是 grounding/box 专家。ETwP是 pointing/path 专家。- Unified RFT 初步整合。
- OPD 把专家能力压进统一模型。
这说明 DeepSeek 的内部路线可能是:底座模型通过 V4 架构支持长上下文和低成本推理;各类专业能力用专家化 post-training 学出来;最终用 OPD 合并。多模态视觉原语只是这个范式在视觉推理上的一次集中体现。
14. 我对论文结论的审慎评价
Section titled “14. 我对论文结论的审慎评价”这篇论文很强,但需要分清“已证明”和“还需证明”。
已证明得比较扎实的部分
Section titled “已证明得比较扎实的部分”- 在计数、空间关系、拓扑类任务上,显式视觉原语确实能提升表现。
- 视觉 token/KV cache 压缩与坐标原语结合,可以在低视觉 token 预算下保持较强推理能力。
- 程序化 synthetic tasks + verifier-driven RL 是训练空间推理能力的有效方式。
- box 与 point 分专家训练再合并,比直接混合所有模式更合理。
仍需更多证据的部分
Section titled “仍需更多证据的部分”- 缺少更完整 ablation:例如同样数据但不输出视觉原语、同样 V4-Flash 但无 cold-start、同样 verifier 但无 OPD。
- in-house benchmark 很关键,但外部复现需要数据和评测协议开放。
- point-based topological reasoning 在真实世界跨场景泛化仍是论文自己承认的限制。
- 当前能力依赖 trigger words,说明模型还没完全学会自动决定何时调用视觉原语。
- 高分辨率细节仍受限,说明 Reference Gap 和 Perception Gap 需要联合解决。
15. 后续研究方向
Section titled “15. 后续研究方向”我建议关注以下方向:
-
自动触发视觉原语
- 让模型根据任务不确定性自动决定是否输出 box/point。
- 可用 policy head 或 tool-use style router。
-
Perception + Reference 联合
- 先用低 token 全图推理识别候选区域。
- 对关键区域触发 high-res crop。
- 再用 visual primitives 绑定对象和轨迹。
-
更丰富的视觉原语
- mask:适合不规则物体。
- polygon:适合文档、地图、CAD。
- line/curve:适合路径与图形题。
- relation graph:适合多对象结构推理。
-
隐藏推理、显式证据
- 不暴露完整 CoT。
- 只输出 answer + visual evidence + concise rationale。
- 更适合产品和安全合规。
-
视觉原语 verifier 标准化
- 建立通用坐标 schema。
- 建立 overlay-based evaluation。
- 建立 rule-based + model-based hybrid reward。
-
从图像扩展到视频与 3D
- video point tracks。
- temporal boxes。
- 3D coordinates / camera-aware grounding。
- 对具身智能和自动驾驶尤其重要。
16. 对团队/研究者的行动建议
Section titled “16. 对团队/研究者的行动建议”如果你要继续深入这条线,我建议这样推进:
-
先复现一个小型 visual-primitives benchmark。
- 选 counting + path tracing 两类即可。
- 输出统一 JSON schema,而不是只输出文本。
-
做一个 overlay viewer。
- 能把
<box>和<point>直接渲染回原图。 - 这是调试和标注质量检查的核心工具。
- 能把
-
设计 verifier。
- counting:box 数量、重复度、IoU、final answer 一致性。
- maze/path:连通性、穿墙、终点、轨迹覆盖。
-
做 ablation。
- text-only CoT。
- final-only grounding。
- interleaved grounding。
- interleaved grounding + verifier RL。
-
再考虑更大模型。
- 这篇论文启示是“接口和数据形态”优先,不是马上堆模型参数。
17. 总结
Section titled “17. 总结”Thinking with Visual Primitives 的核心价值在于,它指出了多模态推理中一个被低估的问题:模型不只是要看清图像,还要在推理过程中稳定引用图像中的具体对象和位置。
它的解决方案非常清晰:
- 用 box 绑定对象。
- 用 point 绑定路径。
- 把这些坐标原语插入思考轨迹。
- 用 verifier 和 RL 训练模型遵守坐标推理。
- 借助 DeepSeek-V4-Flash 的高效长上下文架构,把视觉 token 成本压下来。
从基础研究角度,它是“多模态 CoT 的变量化/可验证化”。从工程角度,它是“把 VLM 输出变成可渲染、可调试、可执行的视觉证据”。这条路线很可能会继续影响 GUI agent、文档视觉理解、机器人路径规划、医学/工业检测等需要强 grounding 的场景。